My publications, ordered by year.
See also Google Scholar for citations. My ORCID.
2026
-

Akshai Srinivasan Sivakumar, Oliver van Kaick
Text to shape generation with finer control
Proc. Int. Conf. on Pattern Recognition and Artificial Intelligence (ICPRAI), to appear, 2026.
[PDF] [Bib]Generating 3D shapes from text is challenging due to the limited availability of text-to-3D datasets. Existing methods train generative models by conditioning on multi-view CLIP image embeddings of shapes during training and use CLIP text embeddings for inference. However, due to the nature of the CLIP's training dataset, the supported text descriptions lack fine details. In this paper, we explore supervised fine-tuning of CLIP-based shape generation with richer captions that enhance control over the generation. We propose a fine-tuning approach that leverages diffusion models to map multiple text embeddings into the CLIP image embedding space, enabling more precise shape generation on the target dataset. The fine-tuned model adapts to the target dataset while remaining effective on open-set captions.
-

Xiangyu Su, Juzhan Xu, Oliver van Kaick, Kai Xu, Ruizhen Hu
IMR-LLM: Industrial Multi-Robot Task Planning and Program Generation using Large Language Models
IEEE Int. Conf. on Robotics and Automation (ICRA), to appear, 2026.
[PDF] [arXiv] [Bib] [Project page] [Award finalist]In modern industrial production, multiple robots often collaborate to complete complex manufacturing tasks. Large language models (LLMs), with their strong reasoning capabilities, have shown potential in coordinating robots for simple household and manipulation tasks. However, in industrial scenarios, stricter sequential constraints and more complex dependencies within tasks present new challenges for LLMs. To address this, we propose IMR-LLM, a novel LLM-driven Industrial Multi-Robot task planning and program generation framework. Specifically, we utilize LLMs to assist in constructing disjunctive graphs and employ deterministic solving methods to obtain a feasible and efficient high-level task plan. Based on this, we use a process tree to guide LLMs to generate executable low-level programs. Additionally, we create IMR-Bench, a challenging benchmark that encompasses multi-robot industrial tasks across three levels of complexity. Experimental results indicate that our method significantly surpasses existing methods across all evaluation metrics.
2025
-

Christopher Palazzolo, Oliver van Kaick, David Mould
By-Example Synthesis of Vector Textures
Proc. Pacific Graphics, 2025.
[PDF] [DOI] [arXiv] [Bib]We propose a new method for synthesizing an arbitrarily sized novel vector texture given a single raster exemplar. In an analysis phase, our method first segments the exemplar to extract primary textons, secondary textons, and a palette of background colors. Then, it clusters the primary textons into categories based on visual similarity, and computes a descriptor to capture each texton's neighborhood and inter-category relationships. In the synthesis phase, our method first constructs a gradient field with a set of control points containing colors from the background palette. Next, it places primary textons based on the descriptors, in order to replicate a similar texton context as in the exemplar. The method also places secondary textons to complement the background detail. We compare our method to previous work with a wide range of perceptual-based metrics, and show that we are able to synthesize textures directly in vector format with quality similar to methods based on raster image synthesis.
-

Tianshu Zhao, Yanran Guan, Oliver van Kaick
Unsupervised 3D Shape Parsing with Primitive Correspondence
Proc. Pacific Graphics, 2025.
[PDF] [DOI] [Bib]3D shape parsing, the process of analyzing and breaking down a 3D shape into components or parts, has become an important task in computer graphics and vision. Approaches for shape parsing include segmentation and approximation methods. Approximation methods often represent shapes with a set of primitives fit to the shapes, such as cuboids, cylinders, or superquadrics. However, existing approximation methods typically rely on a large number of initial primitives and aim to maximize their coverage of the target shape, without accounting for correspondences among the primitives. In this paper, we introduce a novel 3D shape approximation method that integrates reconstruction and correspondence into a single objective, providing approximations that are consistent across the input set of shapes. Our method is unsupervised but also supports supervised learning. Experimental results demonstrate that integrating correspondences into the fitting process not only provides consistent correspondences across a set of input shapes, but also improves approximation quality when using a small number of primitives. Moreover, although correspondences are estimated in an unsupervised manner, our method effectively leverages this knowledge, leading to improved approximations.
-

Christopher Palazzolo, Oliver van Kaick, David Mould
Breaking art: Synthesizing abstract expressionism through image rearrangement
Computers & Graphics (Proc. Expressive), vol. 129, pp. 104224, 2025.
[PDF] [DOI] [Bib]We present an algorithm that creates interesting abstract expressionist images from segments of an input image. The algorithm operates by first segmenting the input image at multiple scales, then redistributing the resulting segments across the image plane to obtain an aesthetic abstract output. Larger segments are placed using neighborhood-aware descriptors, and smaller segments are arranged in a Poisson disk distribution. In our thorough analysis, we show that our results score highly according to several relevant aesthetic metrics, and that our style is indeed abstract expressionism. The results are visually appealing, provided the exemplar has a somewhat diverse color pallette and some amount of structure.
-
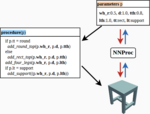
Ishtiaque Hossain, I-Chao Shen, Oliver van Kaick
Approximating Procedural Models of 3D Shapes with Neural Networks
Computer Graphics Forum (Proc. Eurographics), vol. 44, n. 2, pp. 1-15, 2025.
[PDF] [DOI] [Bib]Procedural modeling is a popular technique for 3D content creation and offers a number of advantages over alternative techniques for modeling 3D shapes. However, given a procedural model, predicting the procedural parameters of existing data provided in different modalities can be challenging. This is because the data may be in a different representation than the one generated by the procedural model, and procedural models are usually not invertible, nor are they differentiable. In this paper, we address these limitations and introduce an invertible and differentiable representation for procedural models. We approximate parameterized procedures with a neural network architecture NNProc that learns both the forward and inverse mapping of the procedural model by aligning the latent spaces of shape parameters and shapes. The network is trained in a manner that is agnostic to the inner workings of the procedural model, implying that models implemented in different languages or systems can be used. We demonstrate how the proposed representation can be used for both forward and inverse procedural modeling. Moreover, we show how NNProc can be used in conjunction with optimization for applications such as shape reconstruction from an image or a 3D Gaussian Splatting.
-

Xiangyu Su, Sida Peng, Oliver van Kaick, Hui Huang, Ruizhen Hu
MTScan: Material Transfer from Partial Scans to CAD Models
Lecture Notes in Computer Science (Proc. Computational Visual Media), vol. 15664, pp. 127-146, 2025.
[DOI] [Bib]We introduce a method for transferring material information from a partial scan to a CAD model by establishing a dense correspondence between the scan and the CAD model. Our method is enabled by a pipeline composed of a material decomposition network, a geometry mapping network, and material completion networks. Specifically, given a single RGB-D source image and a target CAD model aligned to the scan, we employ a material decomposition network to extract material and illumination parameters from the image. Next, we sample point clouds from the image and CAD model, and establish a dense correspondence between the two point clouds with a geometry mapping network, which maps the point clouds to a shared template space where correspondences can be derived from closest points and aligned UV maps can be obtained. Finally, based on the established correspondence, we transfer the decomposed material information from the source to the target, and further perform material completion via diffusion on the point clouds and in the UV space. We demonstrate with qualitative and quantitative evaluations that our method is able to obtain more accurate material transfers than previous work in challenging input cases with imperfect shape alignment, so that the shapes with transferred materials better resemble the scanned shapes.
2024
-

Gengxin Liu, Oliver van Kaick, Hui Huang, Ruizhen Hu
Active Self-Training for Weakly Supervised 3D Scene Semantic Segmentation
Journal of Computational Visual Media, vol. 10, n. 3, pp. 425–438, 2024.
[DOI] [arXiv] [Bib]Since the preparation of labeled data for training semantic segmentation networks of point clouds is a time-consuming process, weakly supervised approaches have been introduced to learn from only a small fraction of data. These methods are typically based on learning with contrastive losses while automatically deriving per-point pseudo-labels from a sparse set of user-annotated labels. In this paper, our key observation is that the selection of which samples to annotate is as important as how these samples are used for training. Thus, we introduce a method for weakly supervised segmentation of 3D scenes that combines self-training with active learning. Active learning selects points for annotation that are likely to result in improvements to the trained model, while self-training makes efficient use of the user-provided labels for learning the model. We demonstrate that our approach leads to an effective method that provides improvements in scene segmentation over previous work and baselines, while requiring only a few user annotations.
-
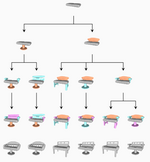
Yanran Guan, Oliver van Kaick
Diverse Part Synthesis for 3D Shape Creation
Computer-Aided Design (Proc. SPM), vol. 175, pp. 103746, 2024.
[DOI] [arXiv] [Bib]Methods that use neural networks for synthesizing 3D shapes in the form of a part-based representation have been introduced over the last few years. These methods represent shapes as a graph or hierarchy of parts and enable a variety of applications such as shape sampling and reconstruction. However, current methods do not allow easily regenerating individual shape parts according to user preferences. In this paper, we investigate techniques that allow the user to generate multiple, diverse suggestions for individual parts. Specifically, we experiment with multimodal deep generative models that allow sampling diverse suggestions for shape parts and focus on models which have not been considered in previous work on shape synthesis. To provide a comparative study of these techniques, we introduce a method for synthesizing 3D shapes in a part-based representation and evaluate all the part suggestion techniques within this synthesis method. In our method, which is inspired by previous work, shapes are represented as a set of parts in the form of implicit functions which are then positioned in space to form the final shape. Synthesis in this representation is enabled by a neural network architecture based on an implicit decoder and a spatial transformer. We compare the various multimodal generative models by evaluating their performance in generating part suggestions. Our contribution is to show with qualitative and quantitative evaluations which of the new techniques for multimodal part generation perform the best and that a synthesis method based on the top-performing techniques allows the user to more finely control the parts that are generated in the 3D shapes while maintaining high shape fidelity when reconstructing shapes.
-

Andre Telfer, Oliver van Kaick, Alfonso Abizaid
Scale-sensitive Mouse Facial Expression Pipeline using a Surrogate Calibration Task
CV4Animals Workshop in CVPR, 2024.
[DOI] [arXiv] [Bib]Emotions are complex neuro-physiological states that influence behavior. While emotions have been instrumental to our survival, they are also closely associated with prevalent disorders such as depression and anxiety. The development of treatments for these disorders has relied on animal models, in particular, mice are often used in pre-clinical testing. To compare effects between treatment groups, researchers have increasingly used machine learning to help quantify behaviors associated with emotionality. Previous work has shown that computer vision can be used to detect facial expressions in mice. In this work, we create a novel dataset for depressive-like mouse facial expressions using varying LypoPolySaccharide (LPS) dosages and demonstrate that a machine learning model trained on this dataset was able to detect differences in magnitude via dosage amount.
2023
-
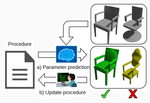
Ishtiaque Hossain, I-Chao Shen, Takeo Igarashi, Oliver van Kaick
Data-guided Authoring of Procedural Models of Shapes
Computer Graphics Forum (Proc. Pacific Graphics), vol. 42, n. 7, pp. e14935, 2023.
[PDF] [DOI] [Bib] [Project page]Procedural models enable the generation of a large amount of diverse shapes by varying the parameters of the model. However, writing a procedural model for replicating a collection of reference shapes is difficult, requiring much inspection of the original and replicated shapes during the development of the model. In this paper, we introduce a data-guided method for aiding a programmer in creating a procedural model to replicate a collection of reference shapes. The user starts by writing an initial procedural model, and the system automatically predicts the model parameters for reference shapes, also grouping shapes by how well they are approximated by the current procedural model. The user can then update the procedural model based on the given feedback and iterate the process. Our system thus automates the tedious process of discovering the parameters that replicate reference shapes, allowing the programmer to focus on designing the high-level rules that generate the shapes. We demonstrate through qualitative examples and a user study that our method is able to speed up the development time for creating procedural models of 2D and 3D man-made shapes.
-

Zejia Su, Qingnan Fan, Xuelin Chen, Oliver van Kaick, Hui Huang, Ruizhen Hu
Scene-aware Activity Program Generation with Language Guidance
Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 42, n. 6, pp. 252:1-252:16, 2023.
[DOI] [Bib] [Project page]We address the problem of scene-aware activity program generation, which requires decomposing a given activity task into instructions that can be sequentially performed within a target scene to complete the activity. While existing methods have shown the ability to generate rational or executable programs, generating programs with both high rationality and executability still remains a challenge. Hence, we propose a novel method where the key idea is to explicitly combine the language rationality of a powerful language model with dynamic perception of the target scene where instructions are executed,to generate programs with high rationality and executability. Our method iteratively generates instructions for the activity program. Specifically, a two-branch feature encoder operates on a language-based and graph-based representation of the current generation progress to extract language features and scene graph features, respectively. These features are then used by a predictor to generate the next instruction in the program. Subsequently, another module performs the predicted action and updates the scene for perception in the next iteration. Extensive evaluations are conducted on the VirtualHome-Env dataset, showing the advantages of our method over previous work. Key algorithmic designs are validated through ablation studies, and results on other types of inputs are also presented to show the generalizability of our method.
-
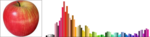
Ruizhen Hu, Ziqi Ye, Bin Chen, Oliver van Kaick, Hui Huang
Self-Supervised Color-Concept Association via Image Colorization
IEEE Transactions on Visualization and Computer Graphics (Proc. InfoVis), vol. 29, n. 1, pp. 247-256, 2023.
[PDF] [DOI] [Bib] [Project page]The interpretation of colors in visualizations is facilitated when the assignments between colors and concepts in the visualizations match human's expectations, implying that the colors can be interpreted in a semantic manner. However, manually creating a dataset of suitable associations between colors and concepts for use in visualizations is costly, as such associations would have to be collected from humans for a large variety of concepts. To address the challenge of collecting this data, we introduce a method to extract color-concept associations automatically from a set of concept images. While the state-of-the-art method extracts associations from data with supervised learning, we developed a self-supervised method based on colorization that does not require the preparation of ground truth color-concept associations. Our key insight is that a set of images of a concept should be sufficient for learning color-concept associations, since humans also learn to associate colors to concepts mainly from past visual input. Thus, we propose to use an automatic colorization method to extract statistical models of the color-concept associations that appear in concept images.
2022
-
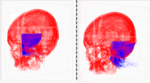
Ding Xia, Xi Yang, Oliver van Kaick, Taichi Kin, Takeo Igarashi
Data-Driven Multi-modal Partial Medical Image Preregistration by Template Space Patch Mapping
Proc. Medical Image Computing and Computer Assisted Intervention (MICCAI) -- Lecture Notes in Computer Science, vol. 13436, pp. 259-268, 2022.
[DOI] [Bib] [Source code] [MICCAI page]Image registration is an essential part of Medical Image Analysis. Traditional local search methods (e.g., Mean Square Errors (MSE) and Normalized Mutual Information (NMI)) achieve accurate registration but require good initialization. However, finding a good initialization is difficult in partial image matching. Recent deep learning methods such as images-to-transformation directly solve the registration problem but need images of mostly same sizes and already roughly aligned. This work presents a learning-based method to provide good initialization for partial image registration. A light and efficient network learns the mapping from a small patch of an image to a position in the template space for each modality. After computing such mapping for a set of patches, we compute a rigid transformation matrix that maps the patches to the corresponding target positions. We tested our method to register a 3DRA image of a partial brain to a CT image of a whole brain. The result shows that MSE registration with our initialization significantly outperformed baselines including naive initialization and recent deep learning methods without template.
-
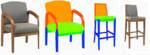
Ruizhen Hu, Xiangyu Su, Xiangkai Chen, Oliver van Kaick, Hui Huang
Photo-to-Shape Material Transfer for Diverse Structures
Trans. on Graphics (Proc. SIGGRAPH), vol. 41, n. 4, pp. 131:1-131:14, 2022.
[PDF] [DOI] [arXiv] [Bib] [Project page]We introduce a method for assigning photorealistic relightable materials to 3D shapes in an automatic manner. Our method takes as input a photo exemplar of a real object and a 3D object with segmentation, and uses the exemplar to guide the assignment of materials to the parts of the shape, so that the appearance of the resulting shape is as similar as possible to the exemplar. To accomplish this goal, our method combines an image translation neural network with a material assignment neural network. The image translation network translates the color from the exemplar to a projection of the 3D shape and the part segmentation from the projection to the exemplar. Then, the material prediction network assigns materials from a collection of realistic materials to the projected parts, based on the translated images and perceptual similarity of the materials. One key idea of our method is to use the translation network to establish a correspondence between the exemplar and shape projection, which allows us to transfer materials between objects with diverse structures. Another key idea of our method is to use the two pairs of (color, segmentation) images provided by the image translation to guide the material assignment, which enables us to ensure the consistency in the assignment. We demonstrate that our method allows us to assign materials to shapes so that their appearances better resemble the input exemplars, improving the quality of the results over the state-of-the-art method, and allowing us to automatically create thousands of shapes with high-quality photorealistic materials.
-
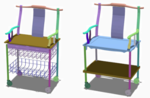
Yanran Guan, Han Liu, Kun Liu, Kangxue Yin, Ruizhen Hu, Oliver van Kaick, Yan Zhang, Ersin Yumer, Nathan Carr, Radomir Mech, Hao Zhang
FAME: 3D Shape Generation via Functionality-Aware Model Evolution
IEEE Transactions on Visualization and Computer Graphics (TVCG), vol. 28, n. 4, pp. 1758-1772, 2022.
[PDF] [DOI] [arXiv] [Bib]We introduce a modeling tool which can evolve a set of 3D objects in a functionality-aware manner. Our goal is for the evolution to generate large and diverse sets of plausible 3D objects for data augmentation, constrained modeling, as well as open-ended exploration to possibly inspire new designs. Starting with an initial population of 3D objects belonging to one or more functional categories, we evolve the shapes through part re-combination to produce generations of hybrids or crossbreeds between parents from the heterogeneous shape collection. Evolutionary selection of offsprings is guided both by a functional plausibility score derived from functional analysis of shapes in the initial population and user preference, as in a design gallery. Since cross-category hybridization may result in offsprings not belonging to any of the known functional categories, we develop a means for functionality partial matching to evaluate functional plausibility on partial shapes. We show a variety of plausible hybrid shapes generated by our functionality-aware model evolution, which can complement existing datasets as training data and boost the performance of contemporary data-driven segmentation schemes, especially in challenging cases.
2021
-
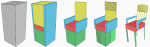
Sharjeel Ali, Oliver van Kaick
Evaluation of Latent Space Learning with Procedurally-Generated Datasets of Shapes
ICCV Workshop on Deep Learning for Geometric Computing, pp. 2086-2094, 2021.
[PDF] [DOI] [Bib] [Project page] [CVF Page]We compare the quality of latent spaces learned by different neural network models for organizing collections of 3D shapes. To accomplish this goal, our first contribution is to introduce a synthetic dataset of shapes with known semantic attributes. We use a procedural method to generate a dataset comprising four categories, with a total of over 10,000 shapes, providing a controlled setting for studying the properties of latent spaces. In contrast to previous work, the synthetic shapes generated with our method have a more realistic appearance, similar to objects in manually-modeled collections. We use 8,800 shapes from the generated dataset to perform a quantitative and qualitative evaluation of the latent spaces learned with a set of representative neural network models. Our second contribution is to perform the quantitative evaluation with measures that we developed for numerically assessing the properties of the latent spaces, which allow us to objectively compare different models based on statistics computed on large sets of shapes.
-
Tansin Jahan, Yanran Guan, Oliver van Kaick
Semantics-Guided Latent Space Exploration for Shape Generation
Computer Graphics Forum (Proc. Eurographics), vol. 40, n. 2, pp. 115-126, 2021.
[PDF] [DOI] [Bib] [Project page]We introduce an approach to incorporate user guidance into shape generation approaches based on deep networks. Generative networks such as autoencoders and generative adversarial networks are trained to encode shapes into latent vectors, effectively learning a latent shape space that can be sampled for generating new shapes. Our main idea is to enable users to explore the shape space with the use of high-level semantic keywords. Specifically, the user inputs a set of keywords that describe the general attributes of the shape to be generated, e.g., “four legs” for a chair. Then, our method maps the keywords to a subspace of the latent space, where the subspace captures the shapes possessing the specified attributes. The user then explores only this subspace to search for shapes that satisfy the design goal, in a process similar to using a parametric shape model. Our exploratory approach allows users to model shapes at a high level without the need for advanced artistic skills, in contrast to existing methods that allow to guide the generation with sketching or partial modeling of a shape. Our technical contribution to enable this exploration-based approach is the introduction of a label regression neural network coupled with shape encoder/decoder networks. The label regression network takes the user-provided keywords and maps them to distributions in the latent space. We show that our method allows users to explore the shape space and generate a variety of shapes with selected high-level attributes.
-
Ruizhen Hu, Bin Chen, Juzhan Xu, Oliver van Kaick, Oliver Deussen, Hui Huang
Shape-driven Coordinate Ordering for Star Glyph Sets via Reinforcement Learning
IEEE Transactions on Visualization and Computer Graphics (TVCG), vol. 27, n. 6, pp. 3034-3047, 2021.
[PDF] [DOI] [Bib]We present a neural optimization model trained with reinforcement learning to solve the coordinate ordering problem for sets of star glyphs. Given a set of star glyphs associated to multiple class labels, we propose to use shape context descriptors to measure the perceptual distance between pairs of glyphs, and use the derived silhouette coefficient to measure the perception of class separability within the entire set. To find the optimal coordinate order for the given set, we train a neural network using reinforcement learning to reward orderings with high silhouette coefficients. The network consists of an encoder and a decoder with an attention mechanism. The encoder employs a recurrent neural network (RNN) to encode input shape and class information, while the decoder together with the attention mechanism employs another RNN to output a sequence with the new coordinate order. In addition, we introduce a neural network to efficiently estimate the similarity between shape context descriptors, which allows to speed up the computation of silhouette coefficients and thus the training of the axis ordering network. Two user studies demonstrate that the orders provided by our method are preferred by users for perceiving class separation. We tested our model on different settings to show its robustness and generalization abilities and demonstrate that it allows to order input sets with unseen data size, data dimension, or number of classes. We also demonstrate that our model can be adapted to coordinate ordering of other types of plots such as RadViz by replacing the proposed shape-aware silhouette coefficient with the corresponding quality metric to guide network training.
2020
-

Ruizhen Hu, Manolis Savva, Oliver van Kaick
Learning 3D Functionality Representations
SIGGRAPH Asia Course Notes, 2020.
[Project page with course materials] [Bib]A central goal of computer graphics is to provide tools for designing and simulating real or imagined artifacts. An understanding of functionality is important in enabling such modeling tools. Given that the majority of man-made artifacts are designed to serve a certain function, the functionality of objects is often reflected by their geometry, the way that they are organized in an environment, and their interaction with other objects or agents. Thus, in recent years, a variety of methods in shape analysis have been developed to extract functional information about objects and scenes from these different types of cues. In this course, we discuss recent developments involving functionality analysis of 3D shapes and scenes. We provide a summary of the state-of-the-art in this area, including a discussion of key ideas and an organized review of the relevant literatures. More specifically, we first present a general definition of functionality from which we derive criteria for classifying the body of prior work. This definition facilitates a comparative view of methods for functionality analysis. Moreover, we connect these methods to recent advances in deep learning, computer vision and robotics. Finally, we discuss a variety of application areas, and outline current challenges and directions for future work.
-
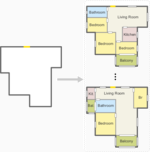
Ruizhen Hu, Zeyu Huang, Yuhan Tang, Oliver van Kaick, Hao Zhang, Hui Huang
Graph2Plan: Learning Floorplan Generation from Layout Graphs
Trans. on Graphics (Proc. SIGGRAPH), vol. 39, n. 4, pp. 118:1-118:14, 2020.
[PDF] [DOI] [Bib]We introduce a learning framework for automated floorplan generation which combines generative modeling using deep neural networks and user-in-the-loop design to enable human users to provide sparse design constraints. Such constraints are represented by a layout graph. The core component of our learning framework is a deep neural network, Graph2Plan, which converts a layout graph, along with a building boundary, into a floorplan that fulfills both the layout and boundary constraints. Given an input building boundary, we allow a user to specify room counts and other layout constraints, which are used to retrieve a set of floorplans, with their associated layout graphs, from a database. For each retrieved layout graph, along with the input boundary, Graph2Plan first generates a corresponding raster floorplan image, and then a refined set of boxes representing the rooms. We demonstrate the quality and versatility of our floorplan generation framework in terms of its ability to cater to different user inputs. We conduct both qualitative and quantitative evaluations, ablation studies, and comparisons with state-of-the-art approaches.
-
Yanran Guan, Tansin Jahan, Oliver van Kaick
Generalized Autoencoder for Volumetric Shape Generation
IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) - CVPR Workshop on Learning 3D Generative Models, pp. 1082-1088, 2020.
[PDF] [DOI] [Bib] [Project page]We introduce a 3D generative shape model based on the generalized autoencoder (GAE). GAEs learn a manifold latent space from data relations explicitly provided during training. In our work, we train a GAE for volumetric shape generation from data similarities derived from the Chamfer distance, and with a loss function which is the combination of the traditional autoencoder loss and the GAE loss. We show that this shape model is able to learn more meaningful structures for the latent manifolds of different categories of shapes, and provides better interpolations between shapes when compared to previous approaches such as autoencoders and variational autoencoders.
2019
-

Zihao Yan, Ruizhen Hu, Xingguang Yan, Luanmin Chen, Oliver van Kaick, Hao Zhang, Hui Huang
RPM-Net: Recurrent Prediction of Motion and Parts from Point Cloud
Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 38, n. 6, pp. 240:1-240:15, 2019.
[PDF] [DOI] [Bib] [Project page]We introduce RPM-Net, a deep learning-based approach which simultaneously infers venue: movable parts and hallucinates their venue: motions from a single, un-segmented, and possibly partial, 3D point cloud shape. RPM-Net is a novel Recurrent Neural Network (RNN), composed of an encoder-decoder pair with interleaved Long Short-Term Memory (LSTM) components, which together predict a temporal sequence of venue: pointwise displacements for the input point cloud. At the same time, the displacements allow the network to learn movable parts, resulting in a motion-based shape segmentation. Recursive applications of RPM-Net on the obtained parts can predict finer-level part motions, resulting in a hierarchical object segmentation. Furthermore, we develop a separate network to estimate part mobilities, e.g., per-part motion parameters, from the segmented motion sequence. Both networks learn deep predictive models from a training set that exemplifies a variety of mobilities for diverse objects. We show results of simultaneous motion and part predictions from synthetic and real scans of 3D objects exhibiting a variety of part mobilities, possibly involving multiple movable parts.
-
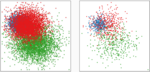
Ruizhen Hu, Tingkai Sha, Oliver van Kaick, Oliver Deussen, Hui Huang
Data Sampling in Multi-view and Multi-class Scatterplots via Set Cover Optimization
IEEE Transactions on Visualization and Computer Graphics (Proc. VIS), vol. 26, n. 1, pp. 739-748, 2019.
[PDF] [DOI] [Bib]We present a method for data sampling in scatterplots by jointly optimizing point selection for different views or classes. Our method uses space-filling curves (Z-order curves) that partition a point set into subsets that, when covered each by one sample, provide a sampling or coreset with good approximation guarantees in relation to the original point set. For scatterplot matrices with multiple views, different views provide different space-filling curves, leading to different partitions of the given point set. For multi-class scatterplots, the focus on either per-class distribution or global distribution provides two different partitions of the given point set that need to be considered in the selection of the coreset. For both cases, we convert the coreset selection problem into an Exact Cover Problem (ECP), and demonstrate with quantitative and qualitative evaluations that an approximate solution that solves the ECP efficiently is able to provide high-quality samplings.
2018
-

Ruizhen Hu, Cheng Wen, Oliver van Kaick, Luanmin Chen, Di Lin, Daniel Cohen-Or, Hui Huang
Semantic Object Reconstruction via Casual Handheld Scanning
Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 37, n. 6, pp. 219:1-219:12, 2018.
[PDF] [DOI] [Bib]We introduce a learning-based method to reconstruct objects acquired in a casual handheld scanning setting with a depth camera. Our method is based on two core components. First, a deep network that provides a semantic segmentation and labeling of the frames of an input RGBD sequence. Second, an alignment and reconstruction method that employs the semantic labeling to reconstruct the acquired object from the frames. We demonstrate that the use of a semantic labeling improves the reconstructions of the objects, when compared to methods that use only the depth information of the frames. Moreover, since training a deep network requires a large amount of labeled data, a key contribution of our work is an active self-learning framework to simplify the creation of the training data. Specifically, we iteratively predict the labeling of frames with the neural network, reconstruct the object from the labeled frames, and evaluate the confidence of the labeling, to incrementally train the neural network while requiring only a small amount of user-provided annotations. We show that this method enables the creation of data for training a neural network with high accuracy, while requiring only little manual effort.
-

Shuhua Li, Ali Mahdavi-Amiri, Ruizhen Hu, Han Liu, Changqing Zou, Oliver van Kaick, Xiuping Liu, Hui Huang, Hao Zhang
Construction and Fabrication of Reversible Shape Transforms
Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 37, n. 6, pp. 190:1-190:14, 2018.
[PDF] [DOI] [Bib]We study a new and elegant instance of geometric dissection of 2D shapes: reversible hinged dissection, which corresponds to a dual transform between two shapes where one of them can be dissected in its interior and then inverted inside-out, with hinges on the shape boundary, to reproduce the other shape, and vice versa. We call such a transform reversible inside-out transform or RIOT. Since it is rare for two shapes to possess even a rough RIOT, let alone an exact one, we develop both a RIOT construction algorithm and a quick filtering mechanism to pick, from a shape collection, potential shape pairs that are likely to possess the transform. Our construction algorithm is fully automatic. It computes an approximate RIOT between two given input 2D shapes, whose boundaries can undergo slight deformations, while the filtering scheme picks good inputs for the construction. Furthermore, we add properly designed hinges and connectors to the shape pieces and fabricate them using a 3D printer so that they can be played as an assembly puzzle. With many interesting and fun RIOT pairs constructed from shapes found online, we demonstrate that our method significantly expands the range of shapes to be considered for RIOT, a seemingly impossible shape transform, and offers a practical way to construct and physically realize these transforms.
-
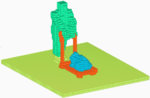
Ruizhen Hu, Zihao Yan, Jingwen Zhang, Oliver van Kaick, Ariel Shamir, Hao Zhang, Hui Huang
Predictive and Generative Neural Networks for Object Functionality
Trans. on Graphics (Proc. SIGGRAPH), vol. 37, n. 4, pp. 151:1-151:13, 2018.
[PDF] [DOI] [Bib]Humans can predict the functionality of an object even without any surroundings, since their knowledge and experience would allow them to "hallucinate" the interaction or usage scenarios involving the object. We develop predictive and generative deep convolutional neural networks to replicate this feat. Specifically, our work focuses on functionalities of man-made 3D objects characterized by human-object or object-object interactions. Our networks are trained on a database of scene contexts, called interaction contexts, each consisting of a central object and one or more surrounding objects, that represent object functionalities. Given a 3D object in isolation, our functional similarity network (fSIM-NET), a variation of the triplet network, is trained to predict the functionality of the object by inferring functionality-revealing interaction contexts involving the object. fSIM-NET is complemented by a generative network (iGEN-NET) and a segmentation network (iSEG-NET). iGEN-NET takes a single voxelized 3D object and synthesizes a voxelized surround, i.e., the interaction context which visually demonstrates the object's functionalities. iSEG-NET separates the interacting objects into different groups according to their interaction types.
-

Diego Gonzalez, Oliver van Kaick
3D Synthesis of Man-made Objects based on Fine-grained Parts
Computers & Graphics (Proc. Shape Modeling International), vol. 74, pp. 150-160, 2018.
[PDF] [DOI] [Bib] [Code]We present a novel approach for 3D shape synthesis from a collection of existing models. The main idea of our approach is to synthesize shapes by recombining fine-grained parts extracted from the existing models based purely on the objects' geometry. Thus, unlike most previous works, a key advantage of our method is that it does not require a semantic segmentation, nor part correspondences between the shapes of the input set. Our method uses a template shape to guide the synthesis. After extracting a set of fine-grained segments from the input dataset, we compute the similarity among the segments in the collection and segments of the template using shape descriptors. Next, we use the similarity estimates to select, from the set of fine-grained segments, compatible replacements for each part of the template. By sampling different segments for each part of the template, and by using different templates, our method can synthesize many distinct shapes that have a variety of local fine details. Additionally, we maintain the plausibility of the objects by preserving the general structure of the template. We show with several experiments performed on different datasets that our algorithm can be used for synthesizing a wide variety of man-made objects.
-

Ruizhen Hu, Manolis Savva, Oliver van Kaick
Functionality Representations and Applications for Shape Analysis
Computer Graphics Forum (Proc. Eurographics State-of-the-art report), vol. 37, n. 4, pp. 603-624, 2018.
[PDF] [DOI] [Bib]A central goal of computer graphics is to provide tools for designing and simulating real or imagined artifacts. An understanding of functionality is important in enabling such modeling tools. Given that the majority of man-made artifacts are designed to serve a certain function, the functionality of objects is often reflected by their geometry, the way that they are organized in an environment, and their interaction with other objects or agents. Thus, in recent years, a variety of methods in shape analysis have been developed to extract functional information about objects and scenes from these different types of cues. In this report, we discuss recent developments that incorporate functionality aspects into the analysis of 3D shapes and scenes. We provide a summary of the state-of-the-art in this area, including a discussion of key ideas and an organized review of the relevant literature. More specifically, the report is structured around a general definition of functionality from which we derive criteria for classifying the body of prior work. This definition also facilitates a comparative view of methods for functionality analysis. We focus on studying the inference of functionality from a geometric perspective, and pose functionality analysis as a process involving both the geometry and interactions of a functional entity. In addition, we discuss a variety of applications that benefit from an analysis of functionality, and conclude the report with a discussion of current challenges and potential future works.
2017
-
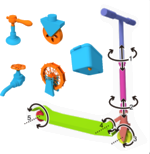
Ruizhen Hu, Wenchao Li, Oliver van Kaick, Ariel Shamir, Hao Zhang, Hui Huang
Learning to Predict Part Mobility from a Single Static Snapshot
Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 36, n. 6, pp. 227:1-227:13, 2017.
[PDF] [DOI] [Bib]We introduce a method for learning a model for the mobility of parts in 3D objects. Our method allows not only to understand the dynamic functionalities of one or more parts in a 3D object, but also to apply the mobility functions to static 3D models. Specifically, the learned part mobility model can predict mobilities for parts of a 3D object given in the form of a single static snapshot reflecting the spatial configuration of the object parts in 3D space, and transfer the mobility from relevant units in the training data. The training data consists of a set of mobility units of different motion types. Each unit is composed of a pair of 3D object parts (one moving and one reference part), along with usage examples consisting of a few snapshots capturing different motion states of the unit. Taking advantage of a linearity characteristic exhibited by most part motions in everyday objects, and utilizing a set of part-relation descriptors, we define a mapping from static snapshots to dynamic units. This mapping employs a motion-dependent snapshot-to-unit distance obtained via metric learning. We show that our learning scheme leads to accurate motion prediction from single static snapshots and allows proper motion transfer. We also demonstrate other applications such as motion-driven object detection and motion hierarchy construction.
-

Ruizhen Hu, Wenchao Li, Oliver van Kaick, Hui Huang, Melinos Averkiou, Daniel Cohen-Or, Hao Zhang
Co-Locating Style-Defining Elements on 3D Shapes
Trans. on Graphics, vol. 36, n. 3, pp. 33:1-33:15, 2017.
[PDF] [DOI] [Bib] [Project page]We introduce a method for co-locating style-defining elements over a set of 3D shapes. Our goal is to translate high-level style descriptions, such as "Ming" or "European" for furniture models, into explicit and localized regions over the geometric models that characterize each style. For each style, the set of style-defining elements is defined as the union of all the elements that are able to discriminate the style. Another property of the style-defining elements is that they are frequently-occurring, reflecting shape characteristics that appear across multiple shapes of the same style. Given an input set of 3D shapes spanning multiple categories and styles, where the shapes are grouped according to their style labels, we perform a cross-category co-analysis of the shape set to learn and spatially locate a set of defining elements for each style. This is accomplished by first sampling a large number of candidate geometric elements, and then iteratively applying feature selection to the candidates, to extract style-discriminating elements until no additional elements can be found. Thus, for each style label, we obtain sets of discriminative elements that together form the superset of defining elements for the style. We demonstrate that the co-location of style-defining elements allows us to solve problems such as style classification, and enables a variety of applications such as style-revealing view selection, style-aware sampling, and style-driven modeling for 3D shapes.
2016
-
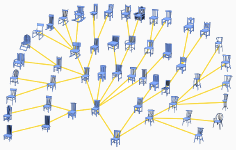
Noa Fish, Oliver van Kaick, Amit Bermano, Daniel Cohen-Or
Structure-oriented Networks of Shape Collections
Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 35, n. 6, pp. 171:1-171:14, 2016.
[PDF] [DOI] [Bib] [Project page]We introduce a co-analysis technique designed for correspondence inference within large shape collections. Such collections are naturally rich in variation, adding ambiguity to the notoriously difficult problem of correspondence computation. We leverage the robustness of correspondences between similar shapes to address the difficulties associated with this problem. In our approach, pairs of similar shapes are extracted from the collection, analyzed and matched in an efficient and reliable manner, culminating in the construction of a network of correspondences that connects the entire collection. The correspondence between any pair of shapes then amounts to a simple propagation along the minimax path between the two shapes in the network. At the heart of our approach is the introduction of a robust, structure-oriented shape matching method. Leveraging the idea of projective analysis, we partition 2D projections of a shape to obtain a set of 1D ordered regions, which are both simple and efficient to match. We lift the matched projections back to the 3D domain to obtain a pairwise shape correspondence. The emphasis given to structural compatibility is a central tool in estimating the reliability and completeness of a computed correspondence, uncovering any non-negligible semantic discrepancies that may exist between shapes. These detected differences are a deciding factor in the establishment of a network aiming to capture local similarities. We demonstrate that the combination of the presented observations into a co-analysis method allows us to establish reliable correspondences among shapes within large collections.
-

Ruizhen Hu, Oliver van Kaick, Bojian Wu, Hui Huang, Ariel Shamir, Hao Zhang
Learning How Objects Function via Co-Analysis of Interactions
Trans. on Graphics (Proc. SIGGRAPH), vol. 35, n. 4, pp. 47:1-47:13, 2016.
[PDF] [DOI] [Bib] [Project page]We introduce a co-analysis method which learns a functionality model for an object category, e.g., strollers or backpacks. Like previous works on functionality, we analyze object-to-object interactions and intra-object properties and relations. Differently from previous works, our model goes beyond providing a functionality-oriented descriptor for a single object; it prototypes the functionality of a category of 3D objects by co-analyzing typical interactions involving objects from the category. Furthermore, our co-analysis localizes the studied properties to the specific locations, or surface patches, that support specific functionalities, and then integrates the patch-level properties into a category functionality model. Thus our model focuses on the how, via common interactions, and where, via patch localization, of functionality analysis. Given a collection of 3D objects belonging to the same category, with each object provided within a scene context, our co-analysis yields a set of proto-patches, each of which is a patch prototype supporting a specific type of interaction, e.g., stroller handle held by hand. The learned category functionality model is composed of proto-patches, along with their pairwise relations, which together summarize the functional properties of all the patches that appear in the input object category. With the learned functionality models for various object categories serving as a knowledge base, we are able to form a functional understanding of an individual 3D object, without a scene context. With patch localization in the model, functionality-aware modeling, e.g, functional object enhancement and the creation of functional object hybrids, is made possible.
2015
-

Yanir Kleiman, Oliver van Kaick, Olga Sorkine-Hornung, Daniel Cohen-Or
SHED: Shape Edit Distance for Fine-grained Shape Similarity
Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 34, n. 6, pp. 235:1-235:11, 2015.
[PDF] [DOI] [Bib] [Project page]Computing similarities or distances between 3D shapes is a crucial building block for numerous tasks, including shape retrieval, exploration and classification. Current state-of-the-art distance measures mostly consider the overall appearance of the shapes and are less sensitive to fine changes in shape structure or geometry. We present shape edit distance (SHED) that measures the amount of effort needed to transform one shape into the other, in terms of rearranging the parts of one shape to match the parts of the other shape, as well as possibly adding and removing parts. The shape edit distance takes into account both the similarity of the overall shape structure and the similarity of individual parts of the shapes. We show that SHED is favorable to state-of-the-art distance measures in a variety of applications and datasets, and is especially successful in scenarios where detecting fine details of the shapes is important, such as shape retrieval and exploration.
-

Ruizhen Hu, Chenyang Zhu, Oliver van Kaick, Ligang Liu, Ariel Shamir, Hao Zhang
Interaction Context (ICON): Towards a Geometric Functionality Descriptor
Trans. on Graphics (Proc. SIGGRAPH), vol. 34, n. 4, pp. 83:1-83:12, 2015.
[PDF] [DOI] [Bib]We introduce a contextual descriptor which aims to provide a geometric description of the functionality of a 3D object in the context of a given scene. Differently from previous works, we do not regard functionality as an abstract label or represent it implicitly through an agent. Our descriptor, called interaction context or ICON for short, explicitly represents the geometry of object-to-object interactions. Our approach to object functionality analysis is based on the key premise that functionality should mainly be derived from interactions between objects and not objects in isolation. Specifically, ICON collects geometric and structural features to encode interactions between a central object in a 3D scene and its surrounding objects. These interactions are then grouped based on feature similarity, leading to a hierarchical structure. By focusing on interactions and their organization, ICON is insensitive to the numbers of objects that appear in a scene, the specific disposition of objects around the central object, or the objects' fine-grained geometry. With a series of experiments, we demonstrate the potential of ICON in functionality-oriented shape processing, including shape retrieval (either directly or by complementing existing shape descriptors), segmentation, and synthesis.
2014
-
Noa Fish, Melinos Averkiou, Oliver van Kaick, Olga Sorkine-Hornung, Daniel Cohen-Or, Niloy J. Mitra
Meta-representation of Shape Families
Trans. on Graphics (Proc. SIGGRAPH), vol. 33, n. 4, pp. 34:1-34:11, 2014.
[PDF] [DOI] [Bib] [Project page]We introduce a meta-representation that represents the essence of a family of shapes. The meta-representation learns the configurations of shape parts that are common across the family, and encapsulates this knowledge with a system of geometric distributions that encode relative arrangements of parts. Thus, instead of predefined priors, what characterizes a shape family is directly learned from the set of input shapes. The meta-representation is constructed from a set of co-segmented shapes with known correspondence. It can then be used in several applications where we seek to preserve the identity of the shapes as members of the family. We demonstrate applications of the meta-representation in exploration of shape repositories, where interesting shape configurations can be examined in the set; guided editing, where models can be edited while maintaining their familial traits; and coupled editing, where several shapes can be collectively deformed by directly manipulating the distributions in the meta-representation. We evaluate the efficacy of the proposed representation on a variety of shape collections.
-

Oliver van Kaick, Noa Fish, Yanir Kleiman, Shmuel Asafi, Daniel Cohen-Or
Shape Segmentation by Approximate Convexity Analysis
Trans. on Graphics, vol. 34, n. 1, pp. 4:1-4:11, 2014.
[PDF] [DOI] [Bib] [Project page including code]We present a shape segmentation method for complete and incomplete shapes. The key idea is to directly optimize the decomposition based on a characterization of the expected geometry of a part in a shape. Rather than setting the number of parts in advance, we search for the smallest number of parts that admit the geometric characterization of the parts. The segmentation is based on an intermediate-level analysis, where first the shape is decomposed into approximate convex components, which are then merged into consistent parts based on a non-local geometric signature. Our method is designed to handle incomplete shapes, represented by point clouds. We show segmentation results on shapes acquired by a range scanner, and an analysis of the robustness of our method to missing regions. Moreover, our method yields results that are comparable to state-of-the-art techniques evaluated on complete shapes.
2013
-

Oliver van Kaick, Kai Xu, Hao Zhang, Yanzhen Wang, Shuyang Sun, Ariel Shamir, Daniel Cohen-Or
Co-Hierarchical Analysis of Shape Structures
Trans. on Graphics (Proc. SIGGRAPH), vol. 32, n. 4, pp. 69:1-69:10, 2013.
[PDF] [DOI] [Bib] [Project page]We introduce an unsupervised co-hierarchical analysis of a set of shapes, aimed at discovering their hierarchical part structures and revealing relations between geometrically dissimilar yet functionally equivalent shape parts across the set. The core problem is that of representative co-selection. For each shape in the set, one representative hierarchy (tree) is selected from among many possible interpretations of the hierarchical structure of the shape. Collectively, the selected tree representatives maximize the within-cluster structural similarity among them. We develop an iterative algorithm for representative co-selection. At each step, a novel cluster-and-select scheme is applied to a set of candidate trees for all the shapes. The tree-to-tree distance for clustering caters to structural shape analysis by focusing on spatial arrangement of shape parts, rather than their geometric details. The final set of representative trees are unified to form a structural co-hierarchy. We demonstrate co-hierarchical analysis on families of man-made shapes exhibiting high degrees of geometric and finer-scale structural variabilities.
-
Oliver van Kaick, Hao Zhang, Ghassan Hamarneh
Bilateral Maps for Partial Matching
Computer Graphics Forum, vol. 32, n. 6, pp. 189-200, 2013.
[PDF] [DOI] [Bib]We introduce the bilateral map, a local shape descriptor whose region of interest is defined by two feature points. Compared to the classical descriptor definition using a single point, the bilateral approach exploits the use of a second point to place more constraints on the selection of the spatial context for feature analysis. This leads to a descriptor where the shape of the region of interest is anisotropic and adapts to the context of the two points, making it more refined for shape analysis, in particular, partial matching.
2012
-
Yunhai Wang, Shmuel Asafi, Oliver van Kaick, Hao Zhang, Daniel Cohen-Or, Baoquan Chen
Active Co-Analysis of a Set of Shapes
Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 31, n. 6, pp. 165:1-165:10, 2012.
[PDF] [DOI] [Bib]Unsupervised co-analysis of a set of shapes is a difficult problem since the geometry of the shapes alone cannot always fully describe the semantics of the shape parts. In this paper, we propose a semi-supervised learning method where the user actively assists in the co-analysis by iteratively providing inputs that progressively constrain the system. We introduce a novel constrained clustering method based on a spring system which embeds elements to better respect their inter-distances in feature space together with the user-given set of constraints. We also present an active learning method that suggests to the user where his input is likely to be the most effective in refining the results. We show that each single pair of constraints affects many relations across the set. Thus, the method requires only a sparse set of constraints to quickly converge toward a consistent and error-free semantic labeling of the set.
2011
-

Oana Sidi, Oliver van Kaick, Yanir Kleiman, Hao Zhang, Daniel Cohen-Or
Unsupervised Co-Segmentation of a Set of Shapes via Descriptor-Space Spectral Clustering
Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 30, n. 6, pp. 126:1-126:9, 2011.
[PDF] [DOI] [Bib] [Project page]We introduce an algorithm for unsupervised co-segmentation of a set of shapes so as to reveal the semantic shape parts and establish their correspondence across the set. The input set may exhibit significant shape variability where the shapes do not admit proper spatial alignment and the corresponding parts in any pair of shapes may be geometrically dissimilar. Our algorithm can handle such challenging input sets since, first, we perform co-analysis in a descriptor space, where a combination of shape descriptors relates the parts independently of their pose, location, and cardinality. Secondly, we exploit a key enabling feature of the input set, namely, dissimilar parts may be ``linked'' through third-parties present in the set. The links are derived from the pairwise similarities between the parts' descriptors. To reveal such linkages which may manifest themselves as anisotropic and non-linear structures in the descriptor space, we perform spectral clustering with the aid of diffusion maps. We show that with our approach, we are able to co-segment sets of shapes that possess significant variability, achieving results that are close to those of a supervised approach.
-

Oliver van Kaick, Andrea Tagliasacchi, Oana Sidi, Hao Zhang, Daniel Cohen-Or, Lior Wolf, Ghassan Hamarneh
Prior Knowledge for Part Correspondence
Computer Graphics Forum (Proc. Eurographics), vol. 30, n. 2, pp. 553-562, 2011.
[PDF] [DOI] [Bib] [Project page]Classical approaches to shape correspondence base their computation purely on the properties, in particular geometric similarity, of the shapes in question. Their performance still falls far short of that of humans in challenging cases where corresponding shape parts may differ significantly in geometry or even topology. We stipulate that in these cases, shape correspondence by humans involves recognition of the shape parts where prior knowledge on the parts would play a more dominant role than geometric similarity. We introduce an approach to part correspondence which incorporates prior knowledge imparted by a training set of pre-segmented, labeled models and combines the knowledge with content-driven analysis based on geometric similarity between the matched shapes. First, the prior knowledge is learned from the training set in the form of per-label classifiers. Next, given two query shapes to be matched, we apply the classifiers to assign a probabilistic label to each shape face. Finally, by means of a joint labeling scheme, the probabilistic labels are used synergistically with pairwise assignments derived from geometric similarity to provide the resulting part correspondence. We show that the incorporation of knowledge is especially effective in dealing with shapes exhibiting large intra-class variations. We also show that combining knowledge and content analyses outperforms approaches guided by either attribute alone.
-

Oliver van Kaick, Hao Zhang, Ghassan Hamarneh, Daniel Cohen-Or
A Survey on Shape Correspondence
Computer Graphics Forum, vol. 30, n. 6, pp. 1681-1707, 2011.
[PDF] [DOI] [Bib] [Project page]We review methods that are designed to compute correspondences between geometric shapes represented by triangle meshes, contours, or point sets. This survey is motivated in part by some recent developments in space-time registration, where one seeks to correspond non-rigid and time-varying surfaces, and semantic shape analysis, which underlines a recent trend to incorporate shape understanding into the analysis pipeline. Establishing a meaningful shape correspondence is often difficult since it generally requires an understanding of the structure of the shapes at both the local and global levels, and sometimes the functionality of the shape parts as well. Despite its inherent complexity, shape correspondence is a recurrent problem and an essential component in numerous geometry processing applications. In this survey, we discuss the different forms of the correspondence problem and review the main solution methods, aided by several classification criteria which can help objectively compare the solutions. We conclude the survey by discussing open problems and future perspectives.
-
Oliver van Kaick
Matching dissimilar shapes
PhD Thesis, Simon Fraser University, Canada, 2011.
[PDF] [Bib]In this thesis, we address the challenge of computing correspondences between dissimilar shapes. This implies that, although the shapes represent the same class of object, there can be major differences in the geometry, topology, and part composition of the shapes as a whole. Additionally, the dissimilarity can also appear in the form of a shape that possesses additional parts that are not present in the other shapes. We propose three approaches for handling such shape dissimilarity. The first two approaches incorporate additional knowledge that goes beyond a direct geometric comparison of the shapes. We show that these approaches allow us to compute correspondences for shapes that differ significantly in their geometry and topology, such as man-made shapes. In the third approach, we compute partial correspondences between shapes that have additional parts in relation to each other. To address this challenge, we propose a new type of shape descriptor, called the bilateral map, whose region of interest is defined by two points. The region of interest adapts to the context of the two points and facilitates the selection of the scale and shape of this region, making this descriptor more effective for partial matching. We demonstrate the advantages of the bilateral map for computing partial and full correspondences between pairs of shapes.
2010
-
Oliver van Kaick, Aaron Ward, Ghassan Hamarneh, Mark Schweitzer, Hao Zhang
Learning Fourier Descriptors for Computer-Aided Diagnosis of the Supraspinatus
Academic Radiology, vol. 17, n. 8, pp. 1040-1049, 2010.
[PDF] [DOI] [Bib]Supraspinatus muscle disorders are frequent and debilitating, resulting in pain and a limited range of shoulder motion. The gold standard for diagnosis involves an invasive surgical procedure. As part of a proposed clinical workflow for noninvasive computer-aided diagnosis (CAD) of the condition of the supraspinatus, we present a method to classify 3D shapes of the muscle into relevant pathology groups, based on magnetic resonance (MR) images. We compute the Fourier coefficients of 2D contours lying on parallel imaging planes and integrate the corresponding frequency components across all contours. To classify the shapes, we learn the Fourier coefficients that best distinguish the different classes. We show that our method leads to significant improvement when compared to previous work. Moreover, we confirm that analyzing the 3D shape of the muscle has potential as a form of diagnosis reinforcement to assess the condition of the supraspinatus.
-

Hao Zhang, Oliver van Kaick, Ramsay Dyer
Spectral Mesh Processing
Computer Graphics Forum, vol. 29, n. 6, pp. 1865-1894, 2010.
[PDF] [DOI] [Bib]Spectral methods for mesh processing and analysis rely on the eigenvalues, eigenvectors, or eigenspace projections derived from appropriately defined mesh operators to carry out desired tasks. Early work in this area can be traced back to the seminal paper by Taubin in 1995, where spectral analysis of mesh geometry based on a combinatorial Laplacian aids our understanding of the low-pass filtering approach to mesh smoothing. Over the past fifteen years, the list of applications in the area of geometry processing which utilize the eigenstructures of a variety of mesh operators in different manners have been growing steadily. Many works presented so far draw parallels from developments in fields such as graph theory, computer vision, machine learning, graph drawing, numerical linear algebra, and high-performance computing. This paper aims to provide a comprehensive survey on the spectral approach, focusing on its power and versatility in solving geometry processing problems and attempting to bridge the gap between relevant research in computer graphics and other fields. Necessary theoretical background is provided. Existing works covered are classified according to different criteria: the operators or eigenstructures employed, application domains, or the dimensionality of the spectral embeddings used. Despite much empirical success, there still remain many open questions pertaining to the spectral approach. These are discussed as we conclude the survey and provide our perspective on possible future research.
2008
-
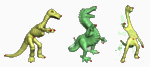
Hao Zhang, Alla Sheffer, Daniel Cohen-Or, Qingnan Zhou, Oliver van Kaick, Andrea Tagliasacchi
Deformation-driven shape correspondence
Computer Graphics Forum (Proc. Symposium on Geometry Processing), vol. 27, n. 5, pp. 1431-1439, 2008.
[PDF] [DOI] [Bib] [Project page]Non-rigid 3D shape correspondence is a fundamental and difficult problem. Most applications which require a correspondence rely on manually selected markers. Without user assistance, the performances of existing automatic correspondence methods depend strongly on a good initial shape alignment or shape prior, and they generally do not tolerate large shape variations. We present an automatic feature correspondence algorithm capable of handling large, non-rigid shape variations, as well as partial matching. This is made possible by leveraging the power of state-of-the-art mesh deformation techniques and relying on a combinatorial tree traversal for correspondence search. The search is deformation-driven, prioritized by a self-distortion energy measured on meshes deformed according to a given correspondence. We demonstrate the ability of our approach to naturally match shapes which differ in pose, local scale, part decomposition, and geometric detail through numerous examples.
2007
-
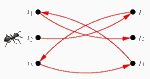
Oliver van Kaick, Ghassan Hamarneh, Hao Zhang, Paul Wighton
Contour Correspondence via Ant Colony Optimization
Proc. Pacific Conference on Computer Graphics and Applications (Pacific Graphics), pp. 271-280, 2007.
[PDF] [DOI] [Bib] [Project page including code]We formulate contour correspondence as a Quadratic Assignment Problem (QAP), incorporating proximity information. By maintaining the neighborhood relation between points this way, we show that better matching results are obtained in practice. We propose the first Ant Colony Optimization (ACO) algorithm specifically aimed at solving the QAP-based shape correspondence problem. Our ACO framework is flexible in the sense that it can handle general point correspondence, but also allows extensions, such as order preservation, for the more specialized contour matching problem.
-
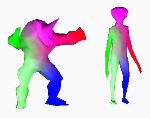
Varun Jain, Hao Zhang, Oliver van Kaick
Non-Rigid Spectral Correspondence of Triangle Meshes
International Journal on Shape Modeling, vol. 13, n. 1, pp. 101-124, 2007.
[PDF] [DOI] [Bib]We present an algorithm for finding a meaningful vertex-to-vertex correspondence between two triangle meshes, which is designed to handle general non-rigid transformations. Our algorithm operates on embeddings of the two shapes in the spectral domain so as to normalize them with respect to uniform scaling and rigid-body transformation. Invariance to shape bending is achieved by relying on approximate geodesic point proximities on a mesh to capture its shape.
2006
-

Oliver van Kaick, Greg Mori
Automatic Classification of Outdoor Images by Region Matching
Proc. Canadian Conference on Computer and Robot Vision (CRV), pp. 1-8, 2006.
[PDF] [DOI] [Bib]This paper presents a novel method for image classification. It differs from previous approaches by computing image similarity based on region matching. Firstly, the images to be classified are segmented into regions or partitioned into regular blocks. Next, low-level features are extracted from each segment or block, and the similarity between two images is computed as the cost of a pairwise matching of regions according to their related features. Experiments are performed to verify that the proposed approach improves the quality of image classification. In addition, unsupervised clustering results are presented to verify the efficacy of this image similarity measure.
-
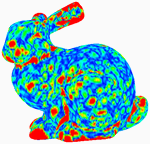
Oliver van Kaick, Hélio Pedrini
A Comparative Evaluation of Metrics for Fast Mesh Simplification
Computer Graphics Forum, vol. 25, n. 2, pp. 197-210, 2006.
[DOI] [Bib]Triangle mesh simplification is of great interest in a variety of knowledge domains, since it allows manipulation and visualization of large models, and it is the starting point for the design of many multiresolution representations. A crucial point in the structure of a simplification method is the definition of an appropriate metric for guiding the decimation process, with the purpose of generating low error approximations at different levels of resolution. This paper proposes two new alternative metrics for mesh simplification, with the aim of producing high quality results with reduced execution time and memory usage, and being simple to implement. A set of different established metrics is also described and a comparative evaluation of these metrics against the two new metrics is performed. A single implementation is used in the experiments, in order to enable the evaluation of these metrics independently from other simplification aspects. Results obtained from the simplification of a number of models, using the different metrics, are compared.
-

Rong Liu, Hao Zhang, Oliver van Kaick
Spectral Sequencing based on Graph Distance
Proc. Geometric Modeling and Processing (GMP), pp. 630-636, 2006.
[PDF] [DOI] [Bib]The construction of linear mesh layouts has found various applications, such as implicit mesh filtering and mesh streaming, where a variety of layout quality criteria, e.g., span and width, can be considered. While spectral sequencing, derived from the Fiedler vector, is one of the best-known heuristics for minimizing width, it does not perform as well as the Cuthill-Mckee (CM) scheme in terms of span. In this paper, we treat optimal mesh layout generation as a problem of preserving graph distances and propose to use the subdominant eigenvector of a kernel (affinity) matrix for sequencing. Despite the non-sparsity of the affinity operators we use, the layouts can be computed efficiently for large meshes through subsampling and eigenvector extrapolation. Our experiments show that the new sequences obtained outperform those derived from the Fiedler vector, in terms of spans, and those obtained from CM, in terms of widths and other important quality criteria. Therefore, in applications where several such quality criteria can influence algorithm performance simultaneously, e.g., mesh streaming and implicit mesh filtering, the new mesh layouts could potentially provide a better trade-off.
2005
-
Oliver van Kaick, Hélio Pedrini
Assessment of Image Surface Approximation Accuracy given by Triangular Meshes
Computational Imaging and Vision (Proc. Int. Conf. on Computer Vision and Graphics), vol. 32, 2005.
[PDF] [DOI] [Bib]This project investigates the use of triangular meshes for approximating digital images, allowing substantial reduction in the cost of storing, manipulating, and rendering surfaces. As an alternative to regular grid models, in which a set of sampled points representing measures of intensity or elevation are stored at regular intervals, the proposed method constructs a set of nonoverlapping contiguous triangular faces which adaptively approximates the data, while preserving relevant features. The data points need not lie in any particular pattern and the density may vary over space.
-
Oliver van Kaick
Métricas para simplificação de malhas triangulares (Metrics for triangle mesh simplification).
Master's Thesis, Federal University of Paraná, Curitiba-PR, Brazil, 2005.
[PDF] [Bib]Triangle mesh simplification is of great interest in a variety of knowledge domains, since it allows manipulation and visualization of large models, and it is the starting point for the design of many multiresolution representations. A crucial point in the structure of a simplification method is the definition of an appropriate metric for guiding the decimation process, with the purpose of generating low error approximations at different levels of resolution. This paper proposes two new alternative metrics for mesh simplification, with the aim of producing high quality results with reduced execution time and memory usage, and being simple to implement. A set of different established metrics is also described and a comparative evaluation of these metrics against the two new metrics is performed. A single implementation is used in the experiments, in order to enable the evaluation of these metrics independently from other simplification aspects. Results obtained from the simplification of a number of models, using the different metrics, are compared.
2004
-

Oliver van Kaick, Murilo V. G. da Silva, Hélio Pedrini
Efficient Generation of Triangle Strips from Triangulated Meshes
Journal of WSCG, vol. 12, n. 1-3, pp. 475-481, 2004.
[PDF] [Bib]The development of methods for storing, manipulating, and rendering large volumes of data efficiently is a crucial task in several scientific applications, such as medical image analysis, remote sensing, computer vision, and computer-aided design. Unless data reduction or compression methods are used, extremely large data sets cannot be analyzed or visualized in real time. Polygonal surfaces, typically defined by a set of triangles, are one of the most widely used representations for geometric models. The aim of this project was to create an efficient algorithm for compressing triangulated models through the construction of triangle strips. Experimental results show that these strips are significantly better than those generated by the leading triangle strip algorithms.
2002
-
Murilo V. G. da Silva, Oliver van Kaick, Hélio Pedrini
Fast Mesh Rendering Through Efficient Triangle Strip Generation
Journal of WSCG, vol. 10, n. 1, pp. 127-134, 2002.
[PDF] [Bib]The development of methods for storing, manipulating, and rendering large volumes of data efficiently is a crucial task in several scientific applications, such as medical image analysis, remote sensing, computer vision, and computer-aided design. Unless data reduction or compression methods are used, extremely large data sets cannot be analyzed or visualized in real time. Polygonal surfaces, typically defined by a set of triangles, are one of the most widely used representations for geometric models. The aim of this project was to create an efficient algorithm for compressing triangulated models through the construction of triangle strips. Experimental results show that these strips are significantly better than those generated by the leading triangle strip algorithms.
-

Oliver van Kaick, Murilo V. G. da Silva, William R. Schwartz, Hélio Pedrini
Fitting Smooth Surfaces to Scattered 3D Data Using Piecewise Quadratic Approximation.
Proc. IEEE Int. Conf. on Image Processing (ICIP), pp. 493-496, 2002.
[PDF] [Bib]The approximation of surfaces to scattered data is an important problem encountered in a variety of scientific applications, such as reverse engineering, computer vision, computer graphics, and terrain modeling. Modeling certain regions as piecewise linear surfaces (C0-continuity surfaces) may require a large number of triangles, whereas a curved surface can provide a more accurate and compact model of the true surface. Smooth surfaces can also produce superior results for rendering purposes, reducing certain perceptual problems such as the appearance of Mach Bands along element boundaries. This project proposes an automatic method for constructing smooth surfaces defined as a network of curved triangular patches. The method starts with a coarse mesh approximating the surface through triangular elements covering the boundary of the domain, then iteratively adds new points from the data set until a specified error tolerance is achieved. Once this initial triangulation has been generated, smooth surfaces are constructed over the triangular mesh. The resulting surface over the triangular mesh is represented by piecewise polynomial patches possessing C1 continuity.
-

Murilo V. G. da Silva, Oliver van Kaick, Olga Regina Pereira Bellon, Luciano Silva
A Hough Transform based Method to Improve Edge Map from Range Images
Proc. Int. Conf. on Computer Vision, Pattern Recognition and Image Processing (CVPRIP), pp. 720-723, 2002.
[Bib]This work proposes an efficient and robust method based on the Hough Transform for the refinement of edge maps from range images. The developed method provides a fast result, preserving the shape of the objects. The method proposed is composed of two stages: (1) the detection of segments of straight lines guided by the Hough Transform; (2) the search among the found straight line segments for those that best describe the object edges.
2001
-
Oliver van Kaick, Murilo V. G. da Silva, Luciano Silva, Olga Regina Pereira Bellon
An Efficient Approach to Improve Edge Detection from Range Images based on Hough Transform
Proc. Image and Vision Computing New Zealand, pp. 219-224, 2001.
[Bib]


